

Haystack é uma estrutura de código aberto conveniente para desenvolver pipelines RAG e aplicações LLM-powered, sendo também a fundação de uma plataforma SaaS útil para a gestão do seu ciclo de vida.

A Haystack é um recurso de software disponível para a criação de aplicações que utilizam modelos de linguagem extensos (LLMs), como aplicações de geração aumentada de recuperação (RAG) e sistemas de busca inteligentes para grandes conjuntos de documentos. Atualmente, a Haystack é desenvolvida exclusivamente em Python.
Haystack serve como a fundação do deepset Cloud, cuja principal patrocinadora é a deepset. Além disso, diversos colaboradores da deepset desempenham um papel significativo no projeto Haystack.
As parcerias com Haystack abrangem modelos disponíveis em plataformas como Hugging Face, OpenAI e Cohere, modelos implementados em plataformas como Amazon SageMaker, Microsoft Azure AI e Google Vertex AI, bem como lojas de vetores e documentos como Elasticsearch, OpenSearch, Pinecone e Qdrant. Adicionalmente, a comunidade Haystack também desenvolveu integrações para ferramentas responsáveis por avaliar modelos, monitorar e importar dados.
Exemplos de aplicações para a Haystack incluem RAG, chatbots, agentes, resposta a perguntas geradas de forma multimodal e extração de informações de documentos. A Haystack oferece recursos que abrangem todas as etapas de projetos de Aprendizado de Máquina por Linguagem (LLM), como integração de fontes de dados, limpeza e pré-processamento de dados, modelos, registro e instrumentação.
Os elementos e fluxos de trabalho do Haystack facilitam a construção de aplicativos. Embora o Haystack tenha vários elementos já prontos, adicionar um elemento personalizado é tão simples quanto criar uma classe em Python. Os fluxos de trabalho conectam os elementos em gráficos ou em múltiplos gráficos (que não precisam ser acíclicos), e o Haystack fornece muitos exemplos de fluxos de trabalho para cenários comuns. Em 12 de agosto, foi anunciado o deepset Studio, um novo produto que permite aos desenvolvedores de IA criar e visualizar fluxos de trabalho personalizados.
Haystack, junto com LlamaIndex, LangChain e Kernel semântico, está entre os quatro principais quadros de aplicação de código aberto mais populares.
Qual é a definição do Haystack?
Haystack é uma estrutura de código aberto para desenvolver aplicações LLM que prioriza a realização correta das tarefas importantes em vez de tentar abranger todas as funcionalidades. Embora não tenha tantas integrações de primeira pessoa como LangChain, Haystack dá suporte total às 34 integrações que possui, além de disponibilizar 28 integrações da comunidade para conectar a estrutura a diferentes recursos. As integrações são destacadas antes da arquitetura central do framework para ressaltar que demandam mais esforço de desenvolvimento do que as capacidades de orquestração central.
Além de enfatizar a realização de tarefas de forma direta em vez de abranger todas as atividades, o Haystack busca ser claro ao invés de sugerir implicitamente. Isso pode implicar em escrever mais código ao criar um pipeline pela primeira vez, porém, em troca desse esforço adicional inicial, você encontrará a depuração, atualização e manutenção do seu pipeline muito mais simples. Para mitigar a dificuldade de escrever uma grande quantidade de código explícito, é possível criar visualmente seus gráficos de pipeline com o Deepset Studio, discutido posteriormente.
Os quatro principais objetivos de design de Haystack devem ser neutros em relação à tecnologia, claros (como acabamos de falar), adaptáveis e expansíveis. O README do repositório do Haystack descreve esses objetivos da seguinte maneira:
- Tecnologia agnóstica: Oferecer aos usuários a liberdade de escolher o fornecedor ou tecnologia desejada e facilitar a troca de qualquer componente por outro. O Haystack permite a utilização e comparação de modelos disponíveis em plataformas como OpenAI, Cohere e Hugging Face, além de modelos personalizados ou locais hospedados em serviços como Azure, Bedrock e SageMaker.
- Parafraseando o texto: Torne-o claro como os componentes móveis podem se comunicar entre si, facilitando a integração de sua variedade de tecnologia e seu uso.
- Flexível: O Haystack oferece uma ampla gama de ferramentas em um único local, incluindo acesso a banco de dados, conversão de arquivos, limpeza, divisão, treinamento, avaliação, inferência e outras funcionalidades. Além disso, é simples criar componentes personalizados quando um comportamento específico é necessário.
- Paráfrase: Permitir que a comunidade e terceiros criem seus próprios componentes de forma simples e consistente, contribuindo para o desenvolvimento de um ambiente aberto em torno do Haystack.
Além de desenvolver aplicativos que melhoram a geração e recuperação de dados usando um banco de dados vetorial, a Haystack pode ser empregada para aprimorar aplicativos de geração aumentada de recuperação, criar agentes (conhecidos como co-pilotos pela Microsoft), responder perguntas, extrair informações, pesquisar semanticamente e desenvolver aplicações que resolvem consultas complexas. Os aplicativos Haystack têm a capacidade de utilizar tanto modelos prontos quanto modelos personalizados para ajuste fino. Caso sejam utilizados modelos multimodais, a Haystack também pode ser empregada para executar geração de imagem, legendar imagens e transcrever áudio.
Ideias fundamentais de Haystack.
Basicamente, o Haystack oferece uma forma de criar pipelines personalizados RAG com LLMs e armazenamentos vetoriais. Ele é estruturado em elementos como componentes, armazenamentos de documentos, classes de dados e pipelines. Vale ressaltar que o Haystack não tem preferência por pesquisa ou incorporação vetorial específica.
Elementos de Haystack
Os elementos da tubulação em Haystack consistem em classes Python com métodos acessíveis diretamente. Essas classes abrangem uma ampla gama de funcionalidades, desde a transcrição de áudio até a criação de documentos. Caso deseje adicionar alguma funcionalidade específica ao seu aplicativo, é possível desenvolver uma nova classe de componente personalizada utilizando a API Componente Haystack. Além disso, se precisar integrar uma API ou banco de dados de terceiros, a API Component facilitará a conexão com seus pipelines, e a Haystack garantirá a validação das conexões entre os componentes antes da execução do pipeline.
Geradores são os elementos que produzem respostas em texto após receberem um estímulo. Eles são adaptados para o modelo de linguagem que utilizam e se dividem em dois tipos: os de chat e os não-chat. Os geradores de chat são voltados para diálogos e requerem uma série de mensagens para o contexto. Já os geradores não-chat são focados na criação de texto direto, como cálculos e traduções.
Os Retrievers em Haystack recuperam documentos de uma loja de documentos que podem ser úteis para uma busca do usuário e enviam esse contexto para o próximo componente em um pipeline, que geralmente é um gerador. Os atributos são personalizados para a loja de documentos que estão sendo acessados.
Estabelecimento especializado em papéis e registros Haystack.
As lojas de documentos são recipientes de informações que guardam os documentos para que possam ser encontrados posteriormente. Elas são feitas para armazenar bases de dados vetoriais, com exceção do InMemoryDocumentStore, que consegue armazenar, processar e recuperar documentos vetoriais de forma autônoma. O InMemoryDocumentStore é mais adequado para o desenvolvimento e testes, porém não é durável o suficiente para ser utilizado em produção.
Os elementos da loja de documentos oferecem suporte a funções como escrever_documentos() e recuperação_bm25(). Além disso, é possível empregar um recurso chamado DocumentWriter para incluir uma série de documentos em uma loja de documentos selecionada. Comumente, os elementos do DocumentWriter são utilizados em um processo de indexação em sequência.
Ensino de informação fornecido pelo Haystack.
As classes de dados facilitam a comunicação entre os componentes da Haystack, permitindo que os dados sejam processados em sequência. Entre as classes de dados da Haystack estão ByteStream, Resposta e suas variações ExtraídasAnswer, ExtraídaTableAnswer e GeneratedAnswer, ChatMessage, Document e StreamingChunk. O Documento pode conter vários tipos de informações, como texto, dataframes, blobs, metadados, pontuação e vetor de incorporação. Já o StreamingChunk representa uma parte de resposta LLM transmitida parcialmente.
Oleodutos em Haystack são tubulações utilizadas para transporte de óleo.
A Pipelines reúne elementos, repositórios de documentos e conexões em sistemas feitos sob medida. Podem ser desde pipelines simples, como um RAG básico que acessa um banco de dados vetorial, solicita informações relevantes e retorna uma resposta, até pipelines complexos ou multi-grafos com fluxos paralelos, elementos autônomos e loops.
Qual é a definição do Deepset Cloud?
O fundo Cloud é uma plataforma baseada em SaaS que permite a criação e gestão de aplicações LLM ao longo de todo o seu ciclo de vida, desde a fase de prototipagem até a produção. Basicamente, é uma versão em nuvem do Haystack, com uma interface gráfica amigável para o desenvolvimento e teste, e uma interface REST para a produção.
Por meio do serviço Cloud Background, é possível realizar o pré-processamento dos dados, prepará-los para pesquisas, criar e avaliar pipelines, além de executar experimentos para verificar o desempenho do pipeline e fazer iterações. Também é viável compartilhar os pipelines com outros usuários para fins de demonstração e teste. O Cloud Background inclui o Studio Prompt para engenharia rápida, escalonamento automático de pipelines implantados e o Studio Deepset para o design visual de pipelines. Os pipelines podem ser criados a partir de um modelo especificado em YAML ou codificados em Python utilizando a API.
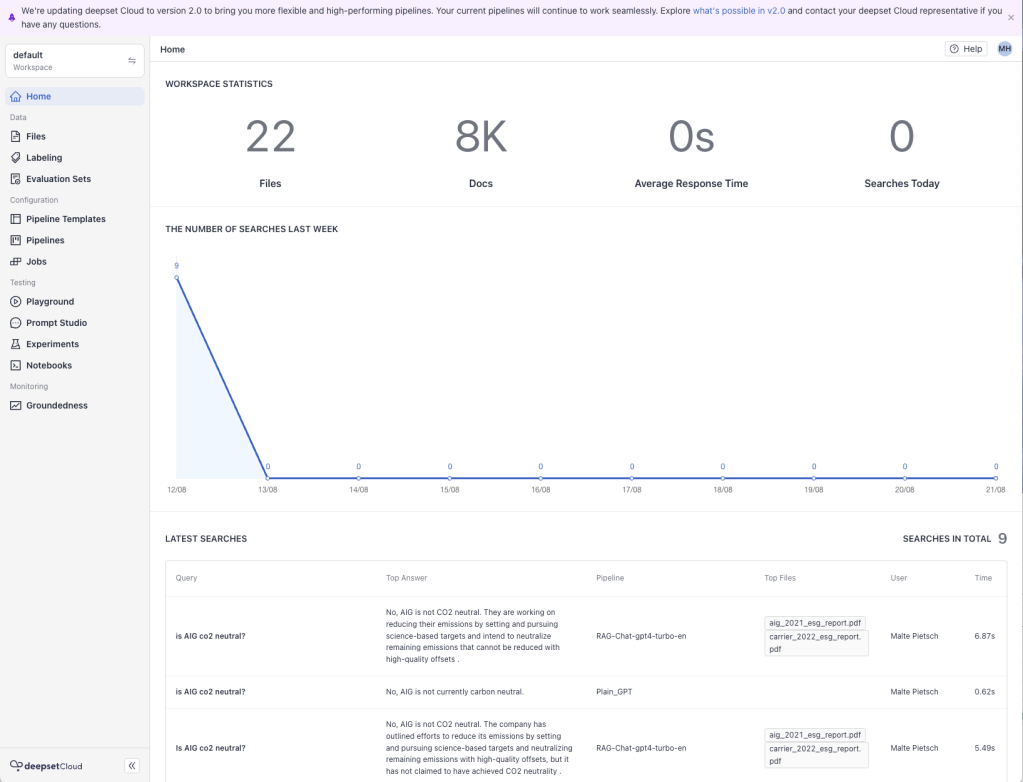
Deepset Cloud Home apresenta um menu de funcionalidades à esquerda e uma lista das pesquisas mais recentes na parte inferior.
Por favor, forneça mais detalhes ou contexto sobre o que você gostaria de parafrasear, pois a palavra “IDG” não contém informações suficientes para ser parafraseada.
Estudio Profundo
deepset Studio é um designer de pipeline visual recém-lançado, atualmente em fase beta restrita e oferecido gratuitamente. Experimentei esta ferramenta na nuvem profunda, mas também pode ser utilizada como um produto independente.
deepset Studio oferece a funcionalidade de arrastar e soltar para acessar a variedade de componentes e integrações da Haystack. É possível visualizar todos os componentes, combiná-los em pipelines, ver suas arquiteturas, alternar entre visualizações de código e visuais, e exportar a configuração final como um arquivo YAML para ser utilizado em diversos ambientes.
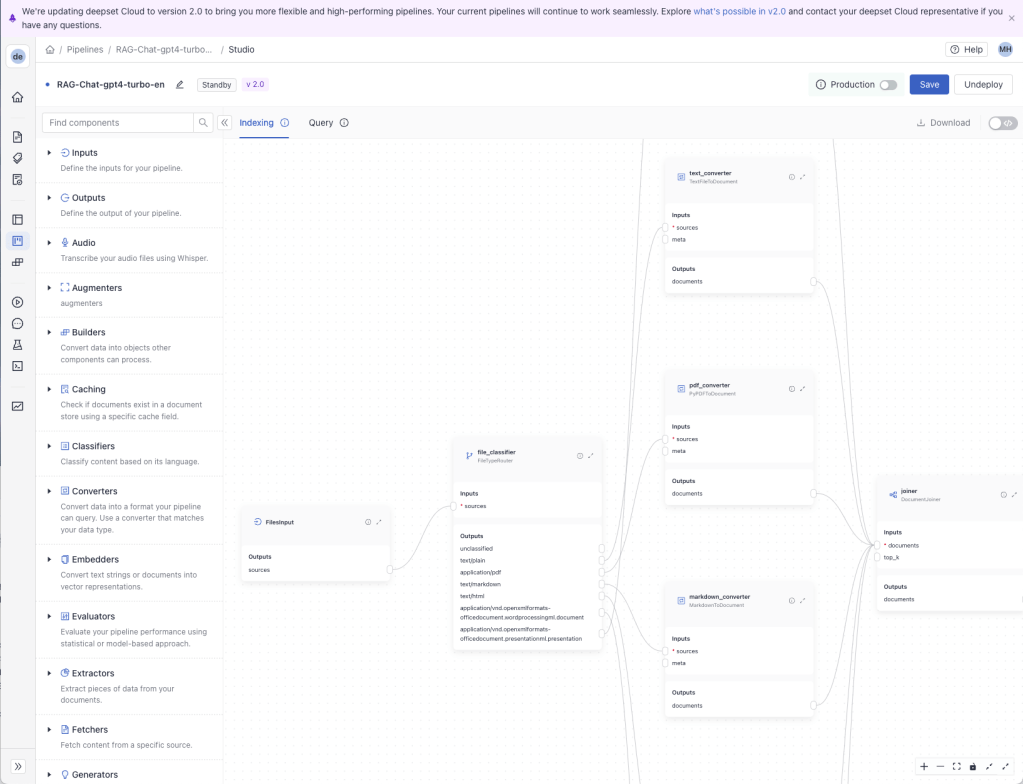
O deepset Studio está sendo executado no deepset Cloud. Este fluxo de trabalho é uma versão simplificada do RAG que processa vários formatos de arquivo para documentos de entrada e inclui a capacidade de interagir com o gpt4-turbo.
Puedo ayudarte, pero necesito más información para poder parafrasear el texto que proporcionaste. ¿Podrías darme más detalles o contexto sobre el texto “IDG”?
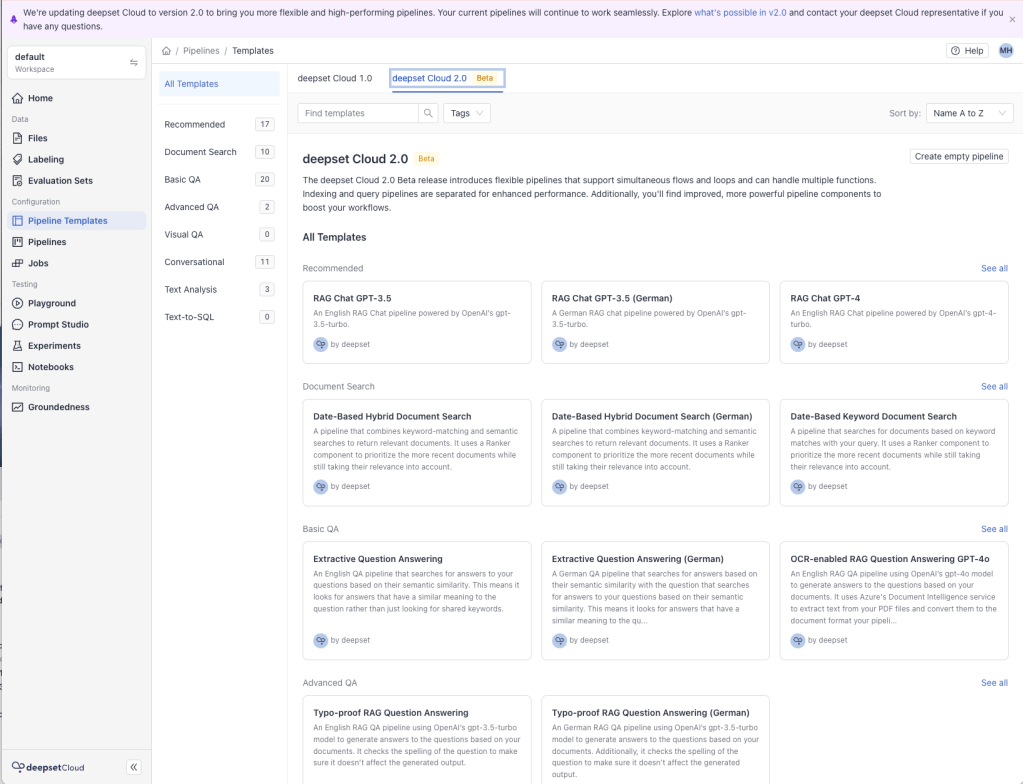
Utilizar modelos de pipeline é uma forma ágil de iniciar com o Haystack no deepset Cloud. Após criar um pipeline a partir de um modelo, é possível personalizá-lo conforme sua necessidade.
Puedes proporcionar más contexto o detalles sobre el texto para que pueda parafrasearlo de manera efectiva.
Iniciar com uma agulha no palheiro.
Conforme mencionado na documentação “iniciar”, é possível instalar o Haystack da seguinte maneira:
Em seguida, é necessário configurar um Haystack Secret ou uma variável de ambiente OPENAI_API_KEY com o valor da sua chave OpenAI. Caso ainda não possua uma chave OpenAI, é possível adquirir uma na plataforma OpenAI, o que pode requerer a inscrição e a disponibilização de um cartão de crédito. É importante não confundir a inscrição para acessar o ChatGPT com a inscrição para acessar a API OpenAI, pois são processos separados. O uso da API é economicamente acessível.
“Copie o código em Python do aplicativo RAG de inicialização extremamente básico da documentação Haystack e cole-o em um editor, como o Visual Studio Code.”
Conforme esperado, o código em Python na linha 31 requer um Segredo do Haystack. Se você escolheu definir uma variável de ambiente, a forma mais simples de alterar a linha 31 é retirar o conteúdo da chamada de função, resultando em:
Isso fará com que a classe Secret seja inicializada com a primeira variável de ambiente encontrada. Para uma especificação mais precisa, é possível utilizar a forma api_key=Secret.from_env(“OPENAI_API_KEY”) ao chamar OpenAIGenerator().
Rode o programa e você deve visualizar o resultado no terminal.
Jean reside na cidade de Paris.
Existe uma explicação rápida (ou guia) disponível no documento que pode ser acessada clicando na caixa localizada abaixo do código identificado como “2.0 RAG Pipeline.” Além disso, é possível obter um entendimento mais aprofundado depurando o código e acompanhando cada chamada de função do Haystack para compreender seu funcionamento. Por fim, é recomendado seguir o link para aprender como incluir dados personalizados utilizando lojas de documentos.
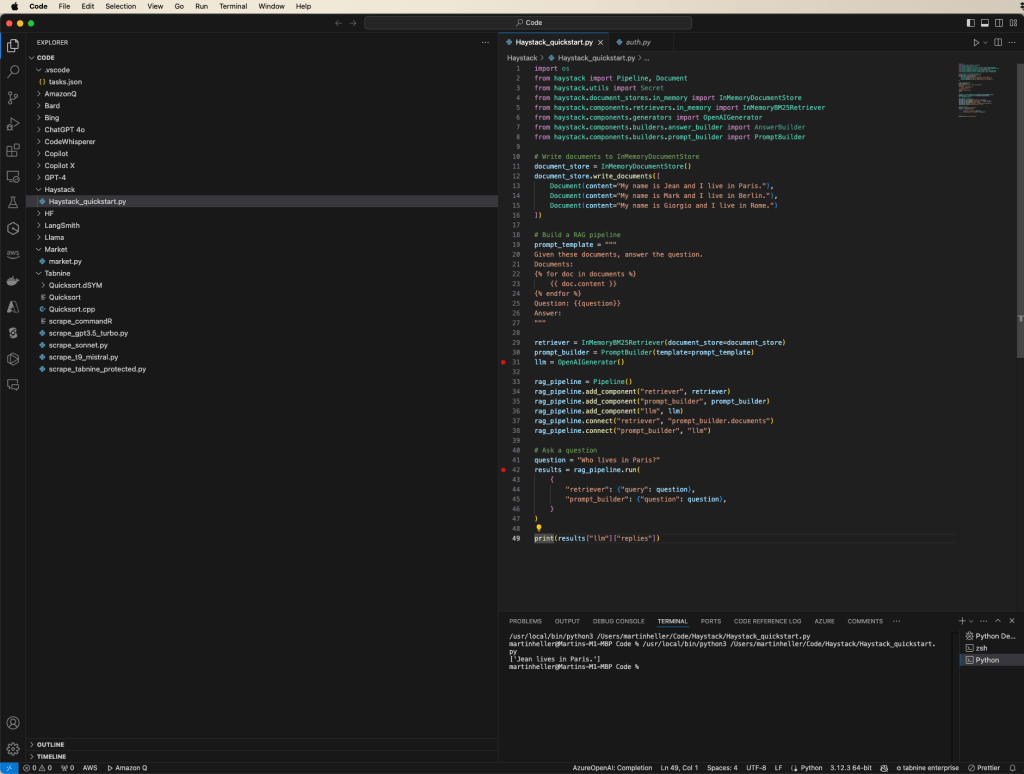
Haystack começa rapidamente a execução do código Python no Visual Studio Code. Anteriormente, exportei a variável de ambiente OPENAI_API_KEY com a minha chave secreta da OpenAI. Além disso, fiz uma modificação na linha 31, conforme explicado acima, para utilizar a variável de ambiente.
Puedo ayudarte con eso, pero necesito más información o contexto sobre el texto “IDG” para poder parafrasearlo. ¿Podrías proporcionarme más detalles sobre el contenido del texto?
Conteúdos educacionais oferecidos por Haystack para auxiliar no aprendizado.
Você pode ampliar seu conhecimento sobre o Haystack consultando a documentação, a API de referência, tutoriais, um livro de receitas, posts no blog e o repositório de código fonte. Além disso, você pode participar de discussões sobre o Haystack no Discord e se inscrever gratuitamente em um curso de uma hora sobre a construção de aplicações de IA com Haystack no DeepLearning.AI. O curso é ministrado por Tuana Çelik, líder de Relações com Desenvolvedores na deepset, empresa por trás do Haystack.
De forma geral, Haystack é um excelente framework de código aberto para desenvolver aplicações LLM, enquanto o deepset Cloud é uma plataforma SaaS de qualidade para construir e gerenciar aplicativos LLM ao longo de todo o ciclo de vida. O deepset Studio é uma ferramenta útil para desenhar pipelines de forma visual; sua versão independente pode transformar diagramas de pipeline em código Python, além de visualizá-los em YAML e diagramas.
Haystack concorre com LlamaIndex, LangChain e Kernel Semântico. Em termos gerais, todos esses frameworks atenderão à maioria dos cenários de uso de aplicativos LLM. Como todos são de código aberto, é possível experimentá-los gratuitamente. Apresentam diferenças em suas ferramentas de depuração, suporte a linguagens de programação e implementações em nuvem. Recomendo testar cada um deles por um ou três dias com um caso de uso simples e claro, a fim de determinar qual deles se adequa melhor às suas necessidades.
Resumo final
A Haystack é uma excelente ferramenta de código aberto para desenvolver aplicações LLM, enquanto a Deepset Cloud é uma plataforma SaaS de qualidade para criação e gerenciamento de aplicações LLM em todas as fases. O deepset Studio é uma ótima ferramenta de design de pipeline visual, e sua versão independente pode transformar diagramas de pipeline em código Python.
Vantagens
- Framework de código aberto para o desenvolvimento de aplicações LLM prontas para serem utilizadas em ambientes de produção.
- Desenvolvido utilizando Python.
- Implementação eficaz de Software como Serviço na nuvem
- Integrações eficazes com diferentes modelos, pesquisa vetorial e diversas ferramentas disponíveis.
- Oferece suporte para monitoramento com as ferramentas Chainlit e Traceloop.
Desculpe, mas preciso de mais contexto ou informações para poder ajudar a parafrasear o texto. Poderia fornecer mais detalhes?
- Nenhuma execução em linguagens de codificação que não sejam o Python.
- deepset Studio ainda está em fase de testes controlados, com exceção do deepset Cloud.
Pode me fornecer mais contexto ou detalhes sobre o texto que gostaria que fosse parafraseado? Isso me ajudaria a fornecer uma paráfrase mais precisa e relevante.
Haystack 2.0 é gratuito. Nuvem deepset: Acesso profundo.
Plataformas de comunicação digital
Python version 3.8 or higher.



