A AWS está desenvolvendo um depurador baseado em LLM para bancos de dados com o objetivo de assumir o controle da OpenAI.
Os pesquisadores da AWS divulgaram um estudo que introduziram um depurador chamado Panda, que utiliza LLM, para combater o GPT-4 da OpenAI.

Os especialistas da AWS estão empenhados em criar um depurador avançado que utiliza um modelo de linguagem para otimizar o desempenho de bancos de dados, visando auxiliar as empresas na resolução de questões de performance nesses sistemas.
Chamado de Panda, o recente sistema de depuração foi desenvolvido para operar de maneira similar a um profissional de banco de dados (DBE), conforme mencionado em um artigo do blog da empresa, que apontou que lidar com questões de desempenho em um banco de dados pode ser desafiador.
Diferentemente dos administradores de banco de dados, cuja responsabilidade é gerenciar múltiplos bancos de dados, os engenheiros de banco de dados têm a função de criar, desenvolver e assegurar a manutenção dos bancos de dados.
Os pesquisadores explicaram que o Panda é uma estrutura que oferece base de contexto para modelos de linguagem pré-treinados, com o objetivo de gerar sugestões de solução de problemas mais relevantes e contextualizadas.
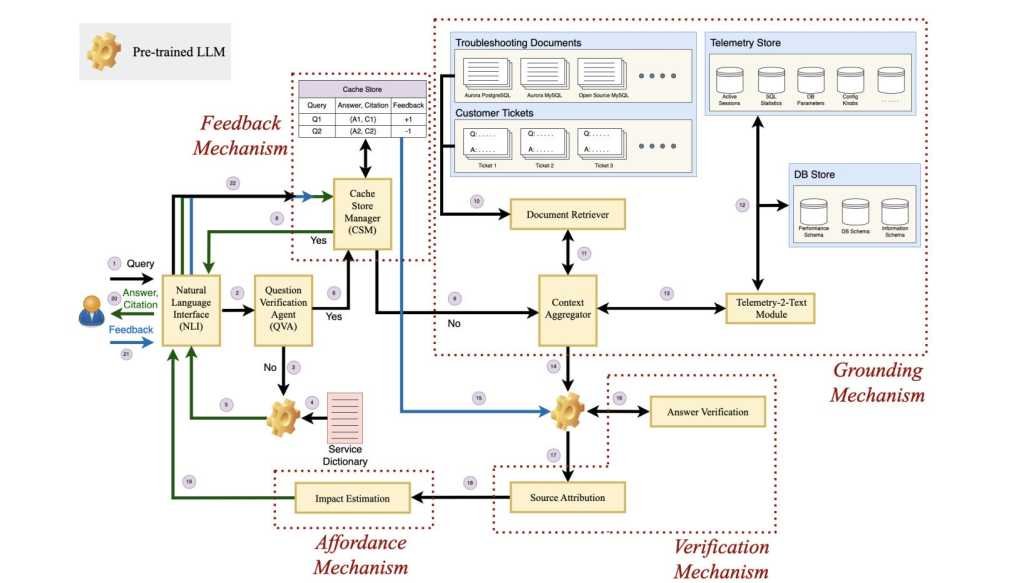
Partes e estrutura do Panda.
O framework engloba quatro elementos fundamentais: base, confirmação, facilidade de acesso e retorno.
Os pesquisadores explicam que a verificação consiste na habilidade do modelo de confirmar a resposta obtida por meio de fontes pertinentes, incluindo a citação correspondente em sua saída para permitir que o usuário final possa verificar.
Por outro lado, os pesquisadores afirmaram que a acessibilidade refere-se à capacidade do framework de alertar o usuário sobre as implicações da ação sugerida por um LLM, destacando claramente ações de alto risco, como DROP ou DELETE.
De acordo com os pesquisadores, o recurso de feedback do Panda possibilita que o depurador LLM baseado nele receba e leve em consideração as opiniões dos usuários ao gerar respostas.
Esses quatro elementos formam a estrutura do depurador, que engloba o agente de questionamento (QVA), o sistema de aterramento, o sistema de verificação, o sistema de retorno e o sistema de disponibilidade.
Enquanto o QVA seleciona e elimina as consultas que não são relevantes, o sistema de aterramento inclui um recuperador de documentos, Telemetry-2-text e um agregador de contexto para adicionar mais informações a um prompt ou consulta.
Os pesquisadores explicaram que a verificação da resposta e a identificação da fonte são parte do processo de verificação, que ocorre em conjunto com o feedback e a acessibilidade em uma interface de linguagem natural utilizada pelo usuário da empresa.
Confronto entre Pitching Panda e o GPT-4 da OpenAI.
Os pesquisadores da AWS lançaram Panda em oposição ao GPT-4 da OpenAI, que é destaque atualmente no ChatGPT.
“…ao apresentarem uma solução para um problema de banco de dados Aurora PostgreSQL, os pesquisadores observaram que buscar assistência do ChatGPT com questões de desempenho do banco de dados frequentemente resulta em sugestões que são consideradas ‘tecnicamente corretas’, porém extremamente ‘vagas’ ou ‘genéricas’, o que pode torná-las inúteis e não confiáveis para engenheiros experientes em bancos de dados (DBEs).”
No experimento conduzido pelos pesquisadores da AWS, foi reunido um grupo de DBEs com diferentes níveis de competência, e a maioria deles demonstrou preferência por Panda, conforme indicado no artigo.
Além disso, especialistas indicaram que o Panda, apesar de ter sido utilizado em bancos de dados em nuvem em sua aplicação anterior, pode ser adaptado para funcionar em qualquer tipo de sistema de banco de dados.